Flink应用实例
记录一个Flink的应用和部署(git repo)。分生产者和消费者,生产者向Kafka发送数据,消费者从Kafka读取数据。架构如下:
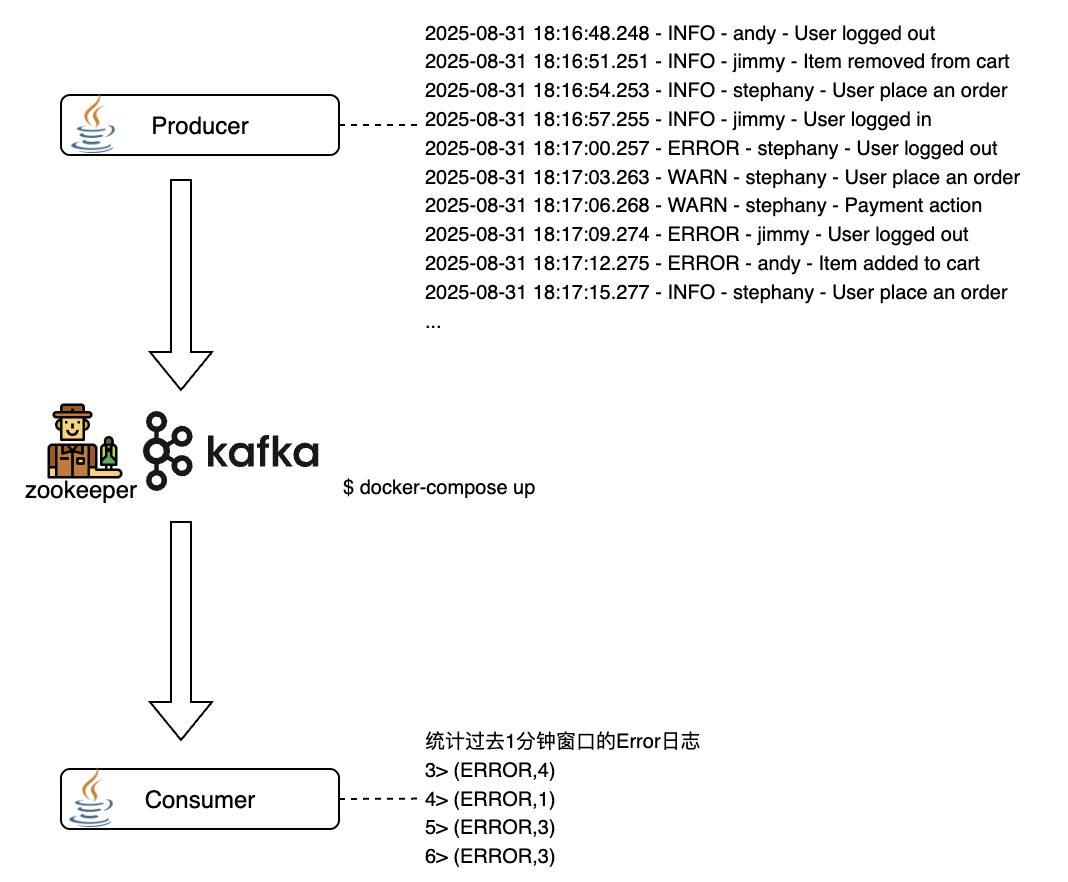
Kafka使用docker部署:
services:
zookeeper:
image: bitnami/zookeeper:3.9
ports:
- "2181:2181"
environment:
- ALLOW_ANONYMOUS_LOGIN=yes
kafka:
image: bitnami/kafka:3.5.0
ports:
- "9092:9092"
- "9093:9093"
environment:
- KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9092
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_CFG_PROCESS_ROLES=broker,controller
- KAFKA_CFG_NODE_ID=1
- KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=1@kafka:9093
- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT
depends_on:
- zookeeper 生产者和消费者都是Java写的,消费者基本处理如下,除了windowAll部分,其他和Spark等没什么区别。
DataStream<String> kafkaStream = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
DataStream<Tuple2<String, Integer>> errorCounts = kafkaStream
.filter(log -> log.contains(" - ERROR - "))
.map(value -> new Tuple2<>("ERROR", 1))
.returns(Types.TUPLE(Types.STRING, Types.INT))
.windowAll(TumblingProcessingTimeWindows.of(Time.minutes(1)))
.sum(1);
errorCounts.print();