讨厌的CSV编码问题
Windows 10操作系统,在将Excel另存为CSV文件时,有两个选择:靠上面的选项是”CSV UTF-8”,靠下面的选项是”CSV”,如果文件中包含中文,自然就选择保存为UTF-8编码,这时,由于某些原因(这些原因包括但不限于因为历史缘故Windows对非英文的默认编码问题),生成的.csv开头会加上3个字节(Hex)”EF BB BF”,这是Unicode中字节顺序(BOM),本来是在UTF-16和UTF-32中用的,Windows却用它来标记编码方式,用在了UTF-8.
Windows的这种做法会导致什么问题呢?首先,如果用程序读取和处理这个CSV文件,会导致开头出现莫名其妙的一个乱码符. Look:
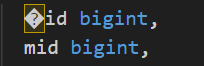
这种情况需要在处理时候把开始的这3个字节丢掉:
final int startIndex = 3;
if (headerBytes.length > startIndex
&& headerBytes[0] == -17
&& headerBytes[1]== -69
&& headerBytes[2]== -65 ){ // EF BB BF
System.out.println("remove BOM!!");
byte[] newbytes = new byte[headerBytes.length - startIndex];
System.arraycopy(headerBytes,
startIndex,
newbytes,
0,
headerBytes.length - startIndex);
header = new String(newbytes, StandardCharsets.UTF_8);
}同样,如果使用别的程序生成的CSV文件,默认是没有这三个开头的bytes的,用其他文本软件打开可能没问题,但用Excel打开就会出现中文乱码情况。这时最好把”EF BB BF”加上。用Java处理实在是太罗嗦了,用Python处理如下:
def add_bytes_to_file(input_file, output_file):
with open(input_file, 'rb') as file:
content = file.read()
with open(output_file, 'wb') as output:
# 添加 EF BB BF 字节
output.write(b'\xEF\xBB\xBF' + content)
print("文件写入成功!")
input_file = 'c:/logs/hh.csv'
output_file = 'c:/logs/hh-hex-py.csv'
add_bytes_to_file(input_file, output_file)还有Windows下,想要查看文本文件的16进制,可以使用下面的命令把文件转一下:
certutil -f -encodehex my-data.csv my-data-hex.csv