小小爬虫
爬虫有风险,使用须谨慎。
科技爱好者周刊内容非常有趣,但也繁杂,检索起来很不方便。为了方便信息查找,使用爬虫获取文本信息,放到数据库中方便搜索。
目的:
- 抓取所有周刊数据,主要想要内容部分,读者评论部分可以不用
- 内容可分: 标题,子标题,文本,图片,链接等(图片没下载)
- 对全部内容做索引,可以方便查询与搜索 (数据量太小12000多条,完全不是大数据)
设计:
- 首先把网页整体下载下来,每期约100K(仅文本),约300期,共需要30M
- 下载使用单线程
- 对下载的网页进一步提取有用信息,并存储为文本(或写入数据库)
- 使用分词,对标题和内容做索引 (没用到)
- 使用命令行,或sql进行查询
主要Challenge:
- 数据结构化存储
- 分词工具没用过
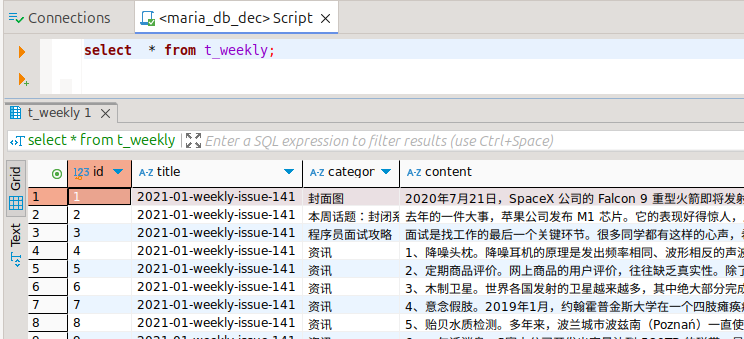
对表的设计很简单,就是一个表存取数据:
DROP TABLE IF EXISTS t_weekly;
CREATE TABLE t_weekly (
id INT NOT NULL AUTO_INCREMENT,
title VARCHAR(255),
category VARCHAR(128),
content TEXT,
url VARCHAR(255),
ctime TIMESTAMP,
utime TIMESTAMP,
last_updated_by VARCHAR(32),
PRIMARY KEY (id)
);下载之后的网页,结构化比较好。使用Beautifulsoup 来处理xpath,获取新闻、文摘、工具、本周话题等信息。但这个地方也是花时间最多的地方,有很多需要处理细节的地方。
部分代码:
def downloads_to(self, base_save_to_folder):
save_to_folder = self.get_save_to_folder()
if save_to_folder == self.ERROR_INVALID_URL:
return self.ERROR_INVALID_URL
save_to = base_save_to_folder + save_to_folder
if not os.path.exists(save_to):
os.makedirs(save_to)
response = requests.get(self.url)
if response.status_code == 200:
with open(save_to + save_to_folder + '.html', "wb") as f:
f.write(response.content)
print("Page saved")
html_content = response.content.decode('utf-8')
pattern = r'<link rel="next" href="(https://[^"]+)"'
match = re.search(pattern, html_content)
if match:
next_link = match.group(1)
return next_link
else:
print(self.ERROR_NO_NEXT_LINK)
return self.ERROR_NO_NEXT_LINK
else:
print(self.ERROR_RESPONSE_CODE, response.status_code)
return self.ERROR_RESPONSE_CODE
def extract_content(self, file_path):
contents_map = {}
with open(file_path, 'r', encoding='utf-8') as reader:
html_content = reader.read()
#print(html)
soup = BeautifulSoup(html_content, 'html.parser')
h1 = soup.find('h1')
category = f'{h1.text}'
contents_map[category] = []
print('Category:', category)
main_content_div = soup.find('div', id='main-content')
paragraphs = main_content_div.find_all(['p', 'h2'])
for tag in paragraphs:
if tag.name == 'h2':
break
if not(tag.text.startswith('这里记录过去一周,我看到的值得分享的东西')
or tag.text.startswith('这里记录每周值得分享的科技内容,周五发布')
or tag.text.startswith('欢迎投稿,或推荐你自己的项目,请前往')
or tag.text.startswith('本杂志开源')
or tag.text.startswith('周刊讨论区的帖子《谁在招人')):
contents_map[category].append(tag.text)
titles = soup.find_all('h2')
for title in titles:
if title.text == '历史上的本周' \
or title.text == '欢迎订阅' \
or title.text == '回顾' :
break
category = f'{title.text}'
print(category)
contents_map[category] = []
next_element = title.find_next_sibling()
while next_element and next_element.name != 'h2':
if next_element.name == 'p' or next_element.name == 'ul' or next_element.name == 'blockquote':
content = next_element.text
content = re.sub(r'\n{2,}', '\n', content)
if bool(re.match(r'\d+、', content)):
content = '~~' + content
if bool(re.match(r'~~\d+、', content)) and len(content) > 4:
content = content + '。'
contents_map[category].append(content)
#print(content)
next_element = next_element.find_next_sibling()
return contents_map可以使用SQL查询了