一个简易RAG系统的实现
RAG(Retrieval Augmented Generation)
RAG叫做检索增强生成系统,它通过知识库+大语言模型为用户提供信息。RAG系统能充分利用企业自身的数据,并结合LLM,因此适合特定知识的搜索,可用来作为智能客服,知识问答助手等等。它的基本构建方式分为两步:
-
知识库的构建,通常需要把企业数据或私有数据转存入向量数据库
-
根据用户问题,检索向量数据库,根据检索结果组合提示词并发给大模型,大模型生成回复
RAG系统具体实现
我之前在网上搜索了一些科技/IT等方面的新闻简报等,这些数据存在本地MySQL中,可以作为构建RAG系统的基础。
第一步,读取MySQL数据,并存入向量数据库ChromaDB;在这一步需要注意,不要使用默认的Embedding模型,而使用对中文支持比较好的一个小模型:BAAI/bge-small-zh-v1.5;并且需要解决文本块太大的问题。文本块拆分有多个策略,比如使用固定最大长度,或使用最大长度并在逗号或句号等地方分割。此处使用固定最大长度,为了防止信息丢失,块和块之间还有部分重叠字符,块大小是500字符,重叠50字符。具体代码如下:
import chromadb
from sentence_transformers import SentenceTransformer
from langchain.text_splitter import RecursiveCharacterTextSplitter
from load_mysql_data import query_data
import sys
from pathlib import Path
sys.path.append(str(Path(__file__).parent.parent))
from appconfig import COLLECTION_NAME
# 加载 BGE-small-zh-v1.5 模型
model = SentenceTransformer('BAAI/bge-small-zh-v1.5')
client = chromadb.PersistentClient(path="./chroma_db")
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # 每个块的最大字符数
chunk_overlap=50, # 块之间的重叠字符数
length_function=len,
)
def remove_collection():
collections = client.list_collections()
for collection in collections:
print(f"Existing collection name: {collection.name}")
if collection.name == COLLECTION_NAME:
client.delete_collection(COLLECTION_NAME)
break
# Run only once
def save_data():
results = query_data()
if not results:
print("No data found.")
return
remove_collection() # remove existing collection which has the same name
collection = client.get_or_create_collection(name=COLLECTION_NAME)
documents = []
document_ids = []
embeddings = []
i = 0
while i < len(results):
row = results[i]
doc_id = str(row['id'])
title = row['title']
pub_date = row['pub_date']
category = row['category'] if row['category'] else "N/A"
content = row['content']
# 拆分content
chunks = text_splitter.split_text(content)
chunk_embeddings = model.encode(chunks).tolist()
chunk_ids = [f"{doc_id}_chunk_{j}" for j in range(len(chunks))]
documents.extend(chunks)
document_ids.extend(chunk_ids)
embeddings.extend(chunk_embeddings)
i += 1
if i % 1000 == 0:
print(f'Saving data {i} ...')
collection.add(
documents=documents,
embeddings=embeddings,
ids=document_ids
)
documents = []
document_ids = []
embeddings = []
if i % 1000 > 0:
collection.add(
documents=documents,
embeddings=embeddings,
ids=document_ids
)
print("数据已成功保存到Chroma DB!")
if __name__ == "__main__":
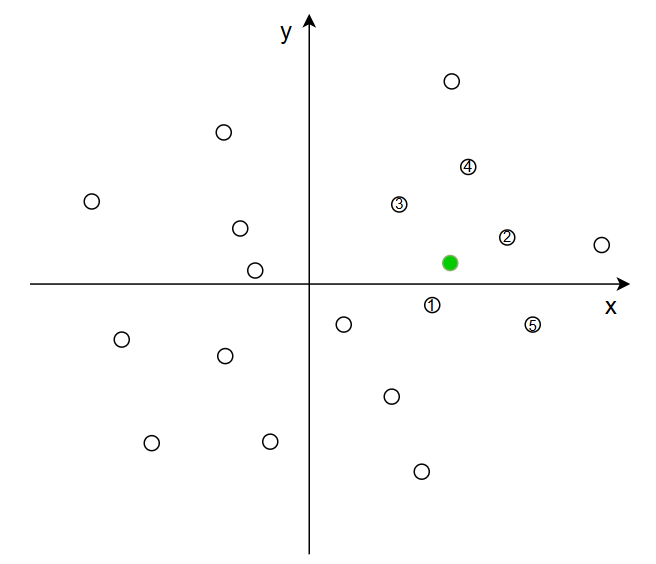
save_data()第二步,结合用户的问题,进行向量搜索,并对结果进行重排。数据向量化之后,可以直接读取,以后只对增量数据写入即可。向量的搜索是一个高维空间的搜索,下面简化为二维表示。其中白色小点表示向量数据库中的数据,绿色小点是用户输入,向量搜索是我们可以搜索离绿色小点最近的n条数据,比如下图中的1~5号数据。
这之中,我们虽然可以找到各数据到用户问题的距离,但为了再准确一些,可以使用模型重新排序,通常做法是使用向量搜索更多条数据,重排后选择小部分数据发给大模型。这里使用的重排模型是BAAI/bge-reranker-base,具体代码如下:
import chromadb
from sentence_transformers import SentenceTransformer
from transformers import AutoModelForSequenceClassification, AutoTokenizer
import torch
import sys
from pathlib import Path
sys.path.append(str(Path(__file__).parent.parent))
from appconfig import COLLECTION_NAME
# 加载 BGE-small-zh-v1.5 模型
model = SentenceTransformer('BAAI/bge-small-zh-v1.5')
reranker_tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-reranker-base')
reranker_model = AutoModelForSequenceClassification.from_pretrained('BAAI/bge-reranker-base')
client = chromadb.PersistentClient(path="./chroma_db")
def query_data(query_text):
collection = client.get_or_create_collection(name=COLLECTION_NAME)
print(f"Chroma DB documents count: {collection.count()}")
query_embedding = model.encode([query_text]).tolist()
# 在集合中搜索相似文档
results = collection.query(
query_embeddings=query_embedding,
n_results=20
)
pairs = []
docs = results['documents'][0]
for doc in docs:
pairs.append([query_text, doc])
# Rerank using bge-reranker
with torch.no_grad():
inputs = reranker_tokenizer(
pairs,
padding=True,
truncation=True,
return_tensors='pt',
max_length=512
)
scores = reranker_model(**inputs).logits.squeeze()
scores = torch.sigmoid(scores) # Convert to probabilities
# from 20 rows and picked the top 5 for GenAI
reranked_results = sorted(zip(docs, scores), key=lambda x: x[1], reverse=True)
return reranked_results[:5]第三步,把选中的数据发给大模型,基于提示词模版,让它返回一个回答。
import google.generativeai as genai
import os
def create_model():
try:
genai.configure(api_key=os.environ["GEMINI_API_KEY"])
except KeyError:
print("Error: The GEMINI_API_KEY environment variable is not set.")
exit()
# Configuration for the model
generation_config = {
"temperature": 0.7,
"top_p": 0.95,
"top_k": 64,
"max_output_tokens": 8192,
}
# Initialize the Generative Model
model = genai.GenerativeModel(
model_name="gemini-2.5-flash",
generation_config=generation_config,
)
return model
def get_prompt(question, text_list):
context = "\n".join([f"[文本{i+1}]: [{text}]" for i, text in enumerate(text_list)])
return f"""
你是一个严谨的信息分析员。请根据下面提供的五段原始文本,综合并回答用户的问题。
请严格遵守以下指令:
1. 你的回答必须完全依据提供的原始文本。
2. 在生成答案时,你需要对关键信息进行引用,并在句末使用类似 [来自文本1]、[来自文本3, 文本4] 的格式注明来源。
3. 综合所有相关信息,形成一个流畅、有逻辑的段落,而不是一个简单的列表。
4. 如果没有任何一段文本能支持回答,请直接回复:“根据提供的文本,我无法回答这个问题。”
[原始文本]
{context}
[用户的问题]
[{question}]
""" 最后,给系统加上UI,可以跟用户交互。这里使用的是streamlit,就不贴了,完整代码请戳这里。